
En la perspectiva más amplia de las tendencias actuales en las operaciones de aplicaciones modernas, los entornos de TI están cambiando con las estrategias de ir a la nube y las iniciativas de modernización de aplicaciones. Existen…
- menos servidores,
- más cargas de trabajo en contenedores,
- más recursos de PaaS en uso,
- más recursos nativos de la nube y sin servidor,
- y potencialmente una adopción de dispositivos IoT a escala.
Cuando se trata de soporte operativo, es obvio que los enfoques tradicionales de monitoreo y gestión de eventos no serán suficientes.
Tradicionalmente, el monitoreo podría detectar que, por ejemplo, un servidor se cae, algún servicio o proceso ha muerto, o alguna métrica observada está fuera del nivel de tolerancia. Entonces es necesario solucionar este problema reiniciando el servidor o el servicio.
Ahora, cuando se utilizan más recursos nativos de la nube en la combinación, es necesario ver más que «algo no funciona» . En entornos de nube, las cosas rara vez se caen por completo, pero incluso si todo funciona bien y todo está verde, podría haber una interrupción causada por otra cosa .
Para este algo más, se necesita un enfoque más sofisticado. Para eso, necesita una plataforma avanzada para el monitoreo, y ahí es donde se puede aprovechar AIOps.
Plataforma AIOps: características clave
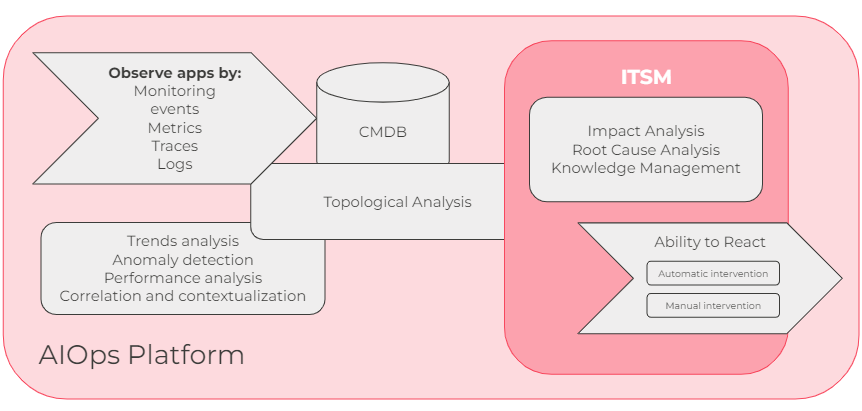
Comencemos con las entradas de datos del monitoreo conectado de todos los tipos, como monitoreo de infraestructura, datos de métricas , seguimientos, es decir, información sobre transacciones y sus latencias, junto con datos de registro.
A partir de ahí, el siguiente paso es el análisis de datos , donde la herramienta puede proporcionar una perspectiva de las tendencias con la capacidad de detectar una anomalía . Además, debemos poder identificar las correlaciones entre las entradas de datos relacionados y redundantes. Para este análisis, la IA se puede utilizar ampliamente.
A continuación, debe poder colocar el problema detectado en el contexto topológico en función de las relaciones y dependencias de CI guardadas en la base de datos de configuración, para saber qué servicios se ven afectados.
Una plataforma AIOps debería poder interactuar con los tickets de ITSM, principalmente con incidentes, problemas y solicitudes de cambio, donde brinda contexto sobre cuál es el impacto potencial y la causa raíz probable . Además, la plataforma combina el problema con soluciones relevantes y conocidas de la base de conocimientos.
El último paso, y probablemente el más importante, es la capacidad de reaccionar con las intervenciones automáticas y manuales con guías de remediación predefinidas.
Si la herramienta tiene todas estas capacidades, puede estar seguro de que es una plataforma AIOps .
Herramientas AIOps en la cartera de ServiceNow
Inteligencia Métrica
Metric Intelligence es un producto que trabaja con datos históricos y utiliza modelos estadísticos. Organiza los datos en una serie temporal y, a partir de ahí, aprende el comportamiento de la infraestructura.
Es entonces cuando Metric Intelligence es capaz de hacer proyecciones para el futuro. Durante la recopilación y evaluación continua de datos, se establecen valores de límites superior e inferior y se descubren automáticamente tendencias o estacionalidades.
Los límites se utilizan para encontrar valores atípicos estadísticos: detección de anomalías . Estas anomalías luego se puntúan/clasifican. Las puntuaciones de anomalías altas para algunas métricas de CI pueden indicar que un CI corre el riesgo de provocar una interrupción del servicio, por lo que las alertas se activan automáticamente.
Supervisión tradicional frente a detección y predicción de anomalías
En el monitoreo tradicional , debe crear umbrales y reglas manualmente. Con el tiempo, se reajustan manualmente aprendiendo de los eventos pasados que ocurrieron en el sistema. A medida que aumenta la complejidad de la infraestructura, las actualizaciones manuales de estos umbrales se vuelven cada vez más complejas y generan espacio para errores, lo que significa costos adicionales.
Por otro lado, con la detección de anomalías, se está enfocando en el comportamiento en una serie de tiempo, a partir de la cual se crean las líneas base. Si hay algo inusual o anormal, se activa una alerta. Además, también puede predecir eventos futuros mediante el uso de tendencias estadísticas.
Con las reglas de eventos y el motor de identificación de CMDB en ServiceNow, los datos recopilados se pueden asignar a CI y desencadenar alertas que son visibles en el espacio de trabajo del operador, o puede ver todos los datos procesados en Insights Explorer .
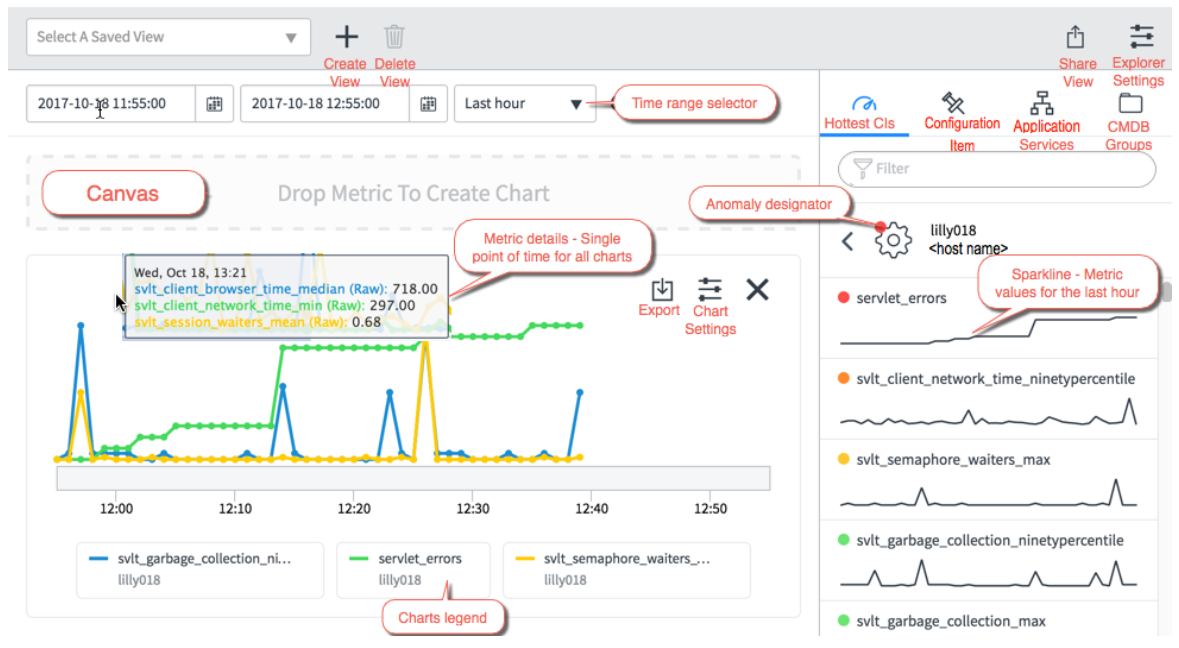
Insights Explorer es una herramienta que muestra estadísticas, gráficos y eventuales anomalías a lo largo de una línea de tiempo. Tiene una vista de varias capas de todas las métricas para cualquier CI en una sola página.
Las opciones de navegación también son muy sencillas. En la parte superior izquierda, puede encontrar el más importante:
- Elementos de configuración más populares para acceder rápidamente a los CI con la mayor cantidad de anomalías.
- Elementos de configuración para crear una lista personalizada separada de cualquier CI de la CMDB, y luego puede arrastrar las métricas correspondientes para estos CI al lienzo.
- Servicios de aplicaciones para crear una lista personalizada de servicios de aplicaciones que le permitan desglosar los CI conectados. Luego, también puede agregar métricas para estos al lienzo.
- Grupos de CMDB para crear una lista personalizada de grupos de CMDB que le permitan profundizar en los elementos de configuración de estos grupos. Luego puede agregar métricas para estos CI al lienzo.
Además, también puede seleccionar el rango de tiempo monitoreado de acuerdo con sus necesidades.
Análisis de registro de salud
Health Log Analytics predice problemas de TI antes de que afecten a sus usuarios. No se trata solo de la recopilación de registros, sino también del análisis de registros.
¿Cómo te ayuda la aplicación a resolver problemas más rápido? Al recopilar, comprender (analizar, normalizar) y correlacionar datos de registro generados por máquinas en tiempo real.
Con el aprendizaje automático, descubre desviaciones del comportamiento normal y, cuando sucede, el sistema lo alerta sobre posibles problemas. También agrupa anomalías y aplica algoritmos adicionales para ayudar a identificar la causa raíz del problema.
Health Log Analytics presenta los datos en un formato lógico y extraído para que los operadores los supervisen en cualquier momento (en el espacio de trabajo del operador ya mencionado). Si es necesario, envía alertas significativas al módulo de gestión de eventos.
Pasos del proceso HLA:
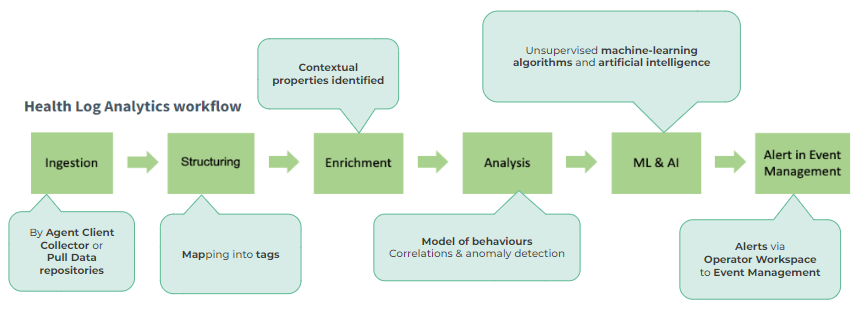
- Ingestión: recopilación de datos con Agent Client Collector o importación de repositorios de datos con un mecanismo de extracción.
- Estructuración: Esta puede ser automática o manual. El sistema extrae la información esencial de las muestras de registro recopiladas, por ejemplo, Mensaje, Marca de tiempo, Host, Severy, ID externas y luego, esta información se asigna automáticamente a las etiquetas apropiadas.
- Enriquecimiento: aquí el sistema identifica palabras clave y propiedades contextuales durante el análisis de datos, que se realiza mediante la ejecución automática de algoritmos (Broker, Patternator, Metricator).
- Análisis: Detección de anomalías, correlación y diagnóstico. Aquí es donde HLA establece modelos de comportamiento, o en otras palabras: establece las expectativas. En base a esto, se pueden detectar comportamientos anómalos (Algoritmos: Métrico, Agregador, Detective, Creador de alertas, Correlador).
- Aprendizaje automático (ML) e inteligencia artificial (IA): la IA se ejecuta en segundo plano, donde los algoritmos de aprendizaje automático avanzados y no supervisados están descubriendo patrones y comportamientos únicos. Luego, ML establece umbrales dinámicos basados en la firma de datos recibidos para identificar posibles problemas. Aquí, también es posible enviar comentarios humanos.
- Alerta en Gestión de Eventos: si el sistema detecta una desviación del patrón típico, envía una alerta a Gestión de Eventos.
Operaciones de confiabilidad del sitio
El objetivo de Site Reliability Operations (SRO) es mostrar el estado del servicio para los equipos de Site Reliability Engineer (SRE). El producto se divide en:
- Operaciones de confiabilidad del sitio
- Métricas de confiabilidad del sitio
Eso indica que funciona con los objetivos y métricas del Servicio, que luego se presentan a los equipos de SRE para respaldar sus operaciones diarias.
Aquí puede ver un gráfico con los pasos de configuración y los elementos del producto:
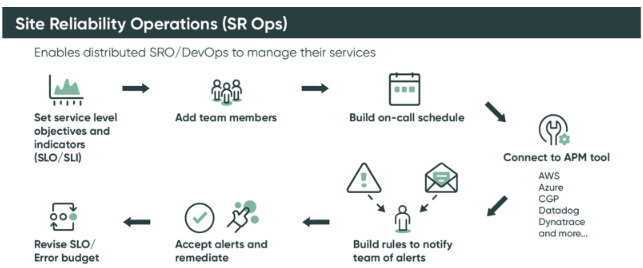
- Componentes relacionados con el servicio: creación y configuración de servicios…
- Agregue un servicio (nómbrelo y agregue un equipo de soporte, cree relaciones con otros servicios, métricas y propiedades, por ejemplo, versión, entorno)
- Integre la herramienta APM del servicio y cree reglas de alerta: hay reglas predefinidas, pero también es posible agregar nuevas reglas, condiciones y acciones para que sucedan, por ejemplo, notificación;
- Crear alertas de nivel de servicio: agregue acciones para realizar, por ejemplo, «crear incidente», «notificación de alerta».
- Componentes operativos:
- Equipos: el equipo SRO se puede crear a través del ‘ Área de trabajo SRO ‘;
- Establecer horarios de guardia para el equipo;
- Agregar miembros del equipo a los turnos;
- Agregue políticas de escalamiento (primario, secundario, general) y reglas sobre quién recibe notificaciones y cuándo.
Site Reliability Metrics (SRM) define 3 tipos de métricas:
- Indicador de nivel de servicio (SLI): utilizado con condiciones de conexión APM, midiendo, por ejemplo, la cantidad de errores, reinicios de la máquina
- Objetivos de nivel de servicio (SLO): donde se establecen los límites y objetivos
- Definición de presupuesto de errores: aquí puede agregar umbrales, establecer cuándo desencadenar acciones para iniciar actividades de alerta o remediación, por ejemplo, enviar notificaciones cuando la cantidad de reinicios pone en peligro el SLO.
Site Reliability Operations Workspace también se puede aprovechar para responder a las alertas. Existe una página específica para los servicios y registros relacionados (alertas o incidencias). Con las tareas de remediación, también puede iniciar, por ejemplo, un incidente o un cambio de tareas.
La próxima semana, presentaremos una herramienta más de gestión de eventos que aprovecha las espléndidas oportunidades de la IA y brindaremos una descripción general de cómo todos estos productos pueden responder a las necesidades actuales de las organizaciones.
No dude en contactarnos para recibir la información más actualizada sobre ServiceNow y sus productos. No dude en comunicarse en caso de que esté interesado en una demostración o servicios profecionales

