
Last week, we wrote about how AIOps support IT operations and described three ServiceNow products – Metric Intelligence, Health Log Analytics and Site Reliability Operations.
As it is closely related to the topic, we need to talk about the exciting concept of observability, which is also unimaginable without AIOps. We will give an overview of one more product from ITOM portfolio called Lightstep, leveraging the newest technology.

First we should clarify what observability is. Traditionally, IT operations have been observing their systems using a set of independent tools to monitor infrastructure from different perspectives, or pillars:
- Logging – recording the individual events that make up a transaction;
- Metrics – recording aggregates of events that make up a transaction;
- Tracing – measuring the latency of operations and identifying performance bottlenecks in a transaction
There are different tools for each perspective. They were born during the evaluation of IT operation, and it led to what is called “three tabs of observability”.
Eventually, this results in an extensive analytical burden. The investigation of an issue usually has three steps using these different tools:
- Noticing that something has happened, and then determining what caused it to happen. Now, in the proactive environment, the investigation starts when someone notices that an important metric goes wrong. Often the only information an operator has at this point is the shape of a tiny line on a dashboard and their own internal assessment as to whether the shape of that line looks “right” or not.
- Having determined the point where the shape of the line started to look somewhat “strange”, the operator would then squint and try to find other lines on the dashboard that went “wrong”. Because these metrics are completely independent of each other, the operator must do the comparison in their brain, without any help from the monitoring tool.
- Now that they have an overview of the problem, the operator usually begins to investigate transactions in log files and resources – like machines, processes, and configuration files that are associated with the problem.
Solving the analytical burden with OpenTelemetry
The computer is of no real help in the process. The logs are stored in a completely separate system and cannot be automatically associated with any metrics on the dashboard. Configuration files and other service-specific information are often in the servers, and operators must remotely connect or otherwise access running machines to look at them and try to correlate. Identifying these logs can be difficult; often the source code must be consulted to even get an idea of what logs might be present.

And this is where OpenTelemetry comes in. OpenTelemetry puts traces, logs, and metrics together in an integrated fashion. All of these connected data points are then transmitted in the same protocol, in the so-called distributed tracing, which can then be input into an observability platform for identifying correlations across the entire data set.

Lightstep: observability platform
Lightstep, the fourth ServiceNow ITOM product using AIOps, is also referred to as an observability platform. It provides a very powerful and comfortable way for developers and site reliability teams to monitor the health of cloud-native applications and the ability to respond to changes or anomalies.
Lightstep is using the distributed tracing (again, in short, the aggregation of metrics, traces and logs built on OpenTelemetry) With this technology, the collected data is integrated into the huge metrics database. where change intelligence is running and providing insights into what happened, and it helps teams to answer the question of what caused the change. Moreover, there is also a possibility of taking actions.
Before diving into this topic more, let’s clarify why we need change intelligence, and why it is getting more and more difficult to find the cause of the incident.
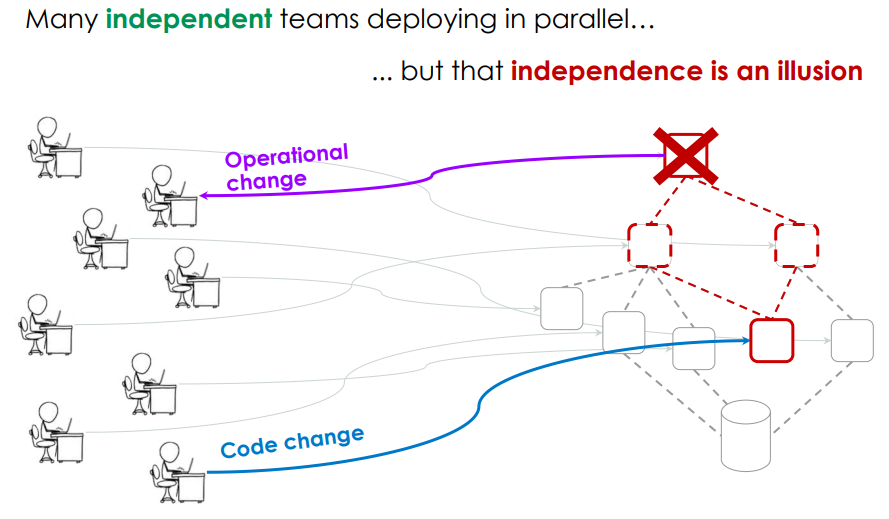
In the cloud environment, micro-services are deployed in different domains and locations by different teams independently and still, the services are not independent, they are all connected. Basically, if there is some change in one micro-service, it may affect another one.
Because of this interconnected infrastructure, where the responsibilities are scattered in different organisations, the time to find the root cause and have it fixed is dramatically increasing. So there is a need for a better solution than the Traditional Monitoring, which shows only the status of the given service.
Lightstep was focusing on this issue with change intelligence and automated root-cause analysis based on distributed tracing. It has built one agent using the previously mentioned OpenTelemetry. This agent is vendor agnostic, because it is an open-source agent. It is compatible with all cloud providers and many others. Moreover external logs and traces can be also added by customers, so the context can be even wider.
Because of using distributed tracing, Lightstep is called an observability tool.
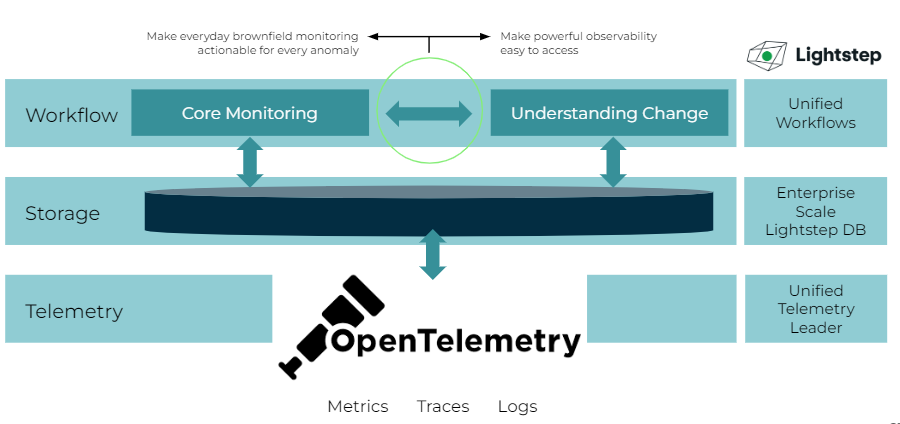
Lightstep has created an integrated dashboard, where you have everything correlated together on a single page for easy operation as you can see on that schema.
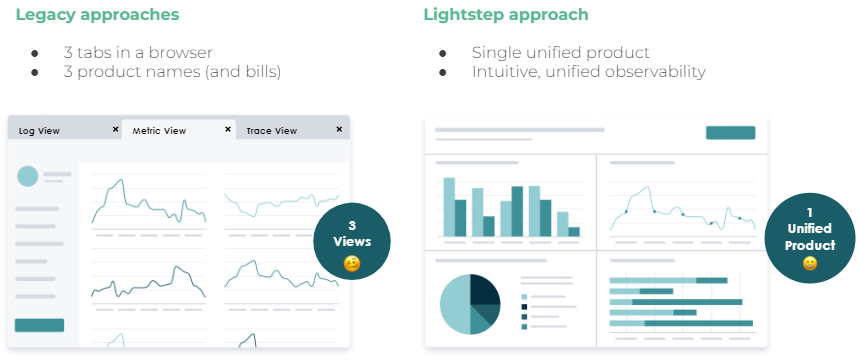
The AI capabilities in the workflow will allow the teams to understand the change and the root cause faster and easier. Engineers and developers can use the workflow links feature to jump into a dedicated logging platform, cloud provider pages or customer support tools. The navigation is easy to use.
When it comes to the storage aspect, Lightstep was designed purposefully to handle a very large volume of transactions generated by Cloud Native Apps. All the transactions can be captured.
Lastly, it is worth mentioning that Lightstep has a Service Graph Connector (SGC) to feed micro-service topology into the CMDB, and the configuration with existing ServiceNow CMDB is very easy.
In the third part of our analysis, we will summarise the four products that we presented. We will put them together and see in which situations organisations can benefit from them the most. Stay tuned!
Don’t hesitate to contact us to receive the most actual information regarding ServiceNow and its products. Feel free to reach out in case you are interested in a demo or professional services.

